從6分鐘介紹 mlops 的影片,我們得知會有三個階段的協作,包含 data engineering 進行 data 的處理產出最後的 dataset,ML engineering 根據 dataset 產生 data model,app engineering 藉由 model 製作 app
data engineering
Curated data(clean, prepare and organize)
The role of the data engineer is to take in raw data and curate (clean, prepare and organize) it for the data scientist to consume
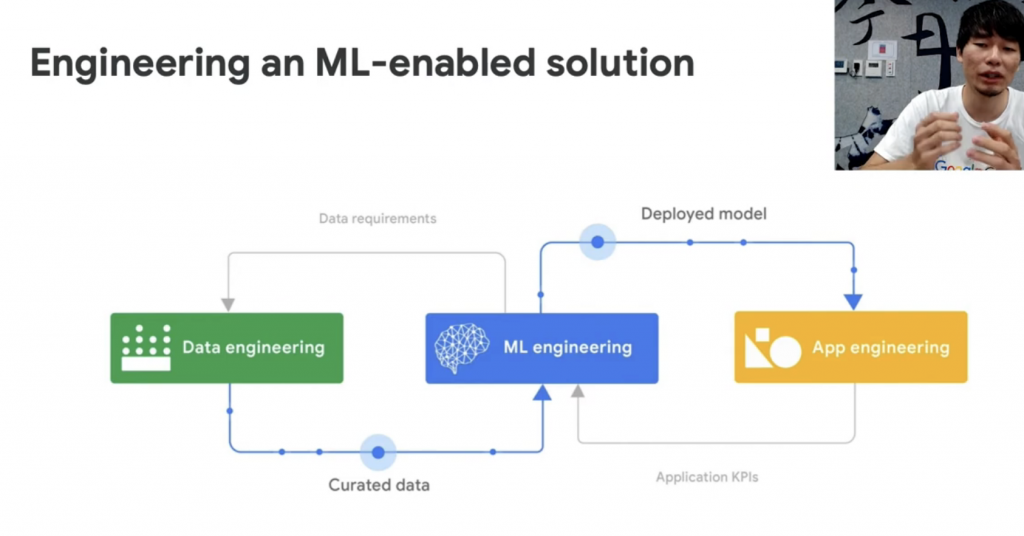
並且我有查到 DPD 這個詞,意味著 from initial curation through to production deployment and ongoing monitoring.
ref: https://www.youtube.com/watch?v=z1hQaqesPos
認真看了一下我們當前的 code,我們是直接引入 transformer model,所以我們應該是不會處理到前面 build model 的部分。transformer model 也稍微瞭解了一下,主要是 Google 提出,採取 注意力機制 的學習模型,特色是藉由上下文去做學習判斷。
研究到這邊,總算比較了解自己的挑戰是什麼。我們應該要盡可能地去找到 pubsub 可以 trigger 的 GCP Resource 並且讓 image 可以直接 run 在系統上。
在研究上目前分成兩條路,一條是改用 pipeline,然後用 Cloud Function with Pub/Sub。我花時間研究了一下 pipeline,為了更了解他在做什麼,並找了一篇 workshop:https://www.youtube.com/watch?v=ATA9t0e1upE
我們先快速介紹一下,ML Pipelines 目的是串接起 ML 中間的每個過程,而 Kubeflow 是一個 toolkit,他提公一個 pipeline 的 solution叫做 Kubeflow Pipelines。而 google 奠基於此體系推出 Vertex AI Pipelines ,有一個簡單的案例幫助大家理解:Kubeflow Pipelines,可以使用Kubernetes 资源(如永久性卷声明)。在Vertex AI Pipelines 中,您的数据存储在Cloud Storage 上,并使用Cloud Storage FUSE 装载到组件中。(ref)
Google Vertex AI 支持两种不同类型的管道:
Kubeflow Pipelines using the Kubeflow SDK ≥ 1.6
使用 Kubeflow SDK ≥ 1.6 的 Kubeflow 管线
TensorFlow Extended Pipelines using the TFX SDK ≥ 0.30.0
使用 TFX SDK 的 TensorFlow 扩展管道 ≥ 0.30.0
以下開始實作最簡單的 pipeline,一個 Pipeline 包含多個 components,component 可能是 Python function or Container。先來簡單實作 python function
在程式碼中安裝 ++Kubeflow Pipelines module++
使用 component 裝士氣
@component()
def concat(a: str, b: str) -> str:
return a + b
使用 pipeline
@pipeline(name="basic-pipeline",
pipeline_root=PIPELINE_ROOT + "basic-pipeline")
def basic_pipeline(a: str='stres', b: str='sed'):
concat_task = concat(a=a, b=b)
reverse_task = reverse(a=concat_task.output)
Compile,將 pipeline compile 成 json file,最後會用此 json file 建立 Vertex AI Pipelines
run job
job = pipeline_jobs.PipelineJob(
display_name="basic-pipeline",
template_path="basic_pipeline.json",
parameter_values={"a": "stres", "b": "sed"}
)
job.run(sync=False)
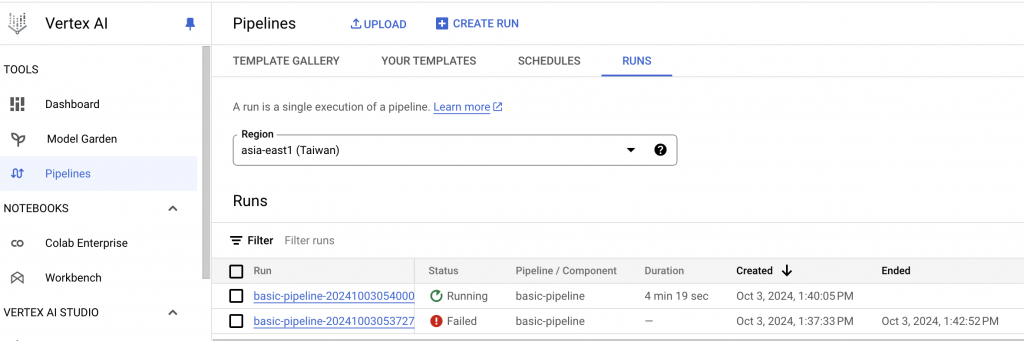
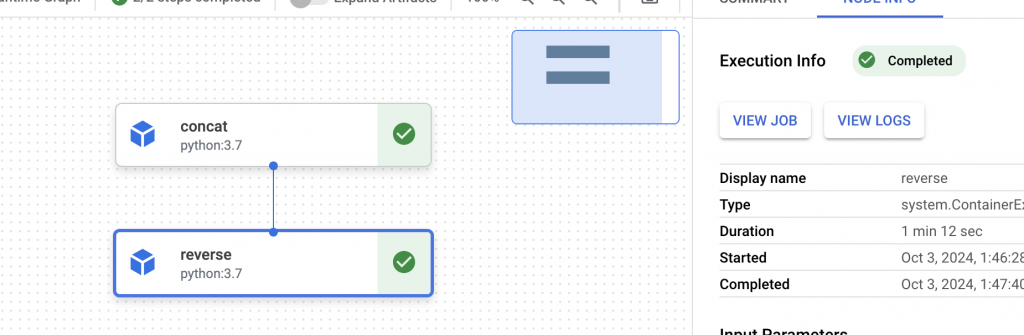
從 job 可以看到他是起一個 node 跟 pod 幫你運行,減少我們需要管 kube 的工。你也可以在 code 中指定 instance type
但這個辦法是要大改 code 的。另一個方法就是將他當作一般的 API Service,但是必須放在 GPU 機器上。缺點雖然是沒辦法看到每個 process,但就是不用改 code。初步查到的資料是 pubsub → eventarc → gke。這邊的 eventarc 跟 AWS eventbridge 有點像,就是轉送服務。這邊可能是從 eventarc sent http post to GKE。
DoD 總結
釐清 storage 環境差別
改用 Vertical AI Workbench 替代開發環境
設計開發上版的 Git 規則(不同環境的打包以及 image version 設計)
設計 CI 及 CD 流程
使用 eventarc 取代當前 subscriber 動作
讓 eventarc 可以打 GKE private endpoint
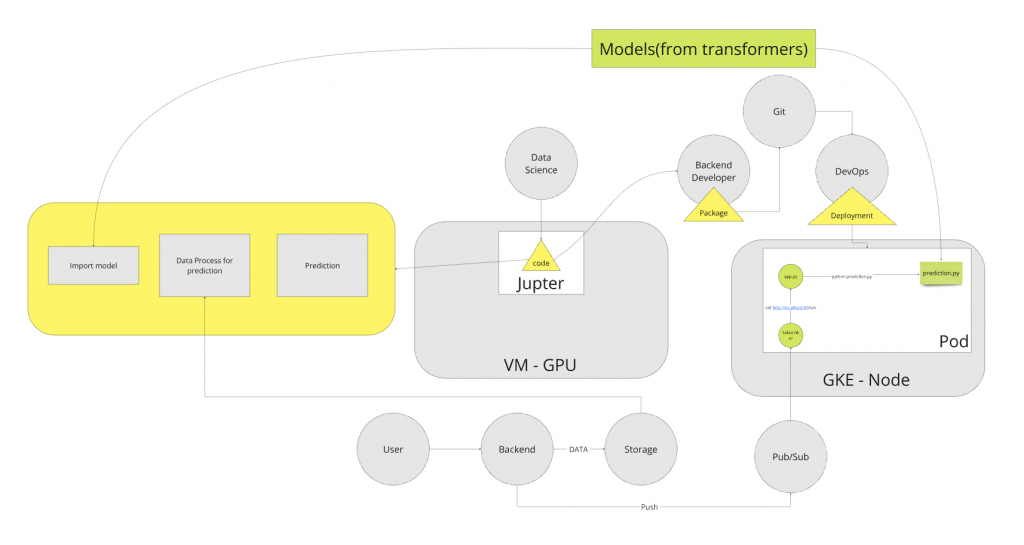
以下為 Before
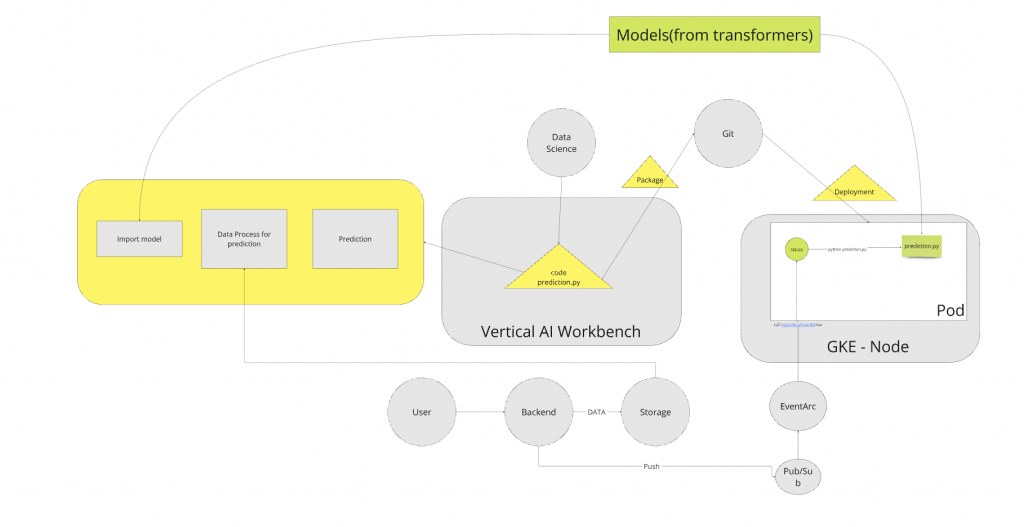
以下為 After


 iThome鐵人賽
iThome鐵人賽